Last edited on 1998-07-04 11:34:50 by stolfi
For these plots, I deleted all word breaks (but not line breaks) in the sample text, and then factored the resulting strings into the character groups, or "elements", of my OKOKOKO paradigm:
a y o
ch sh ee
che she eee
t k p f
te ke pe fe
cth ckh cph cfh
cthe ckhe cphe cfhe
ct ck cp cf
ith ikh iph ifh
d id iid iiid
de
n in iin iiin
r ir iir iiir
l il iil iiil
m im iim iiim
s is iis iiis
j ij iij iiij
g ig iig iiig
q
x b u
The elements in boldface occur more than 15 times in the
whole text; those in italics do not occurr at all.
There were about 300 failures of the OKOKOKO paradigm
(mostly extra "e"s and "i"s), or about 3 every 1000
elements.
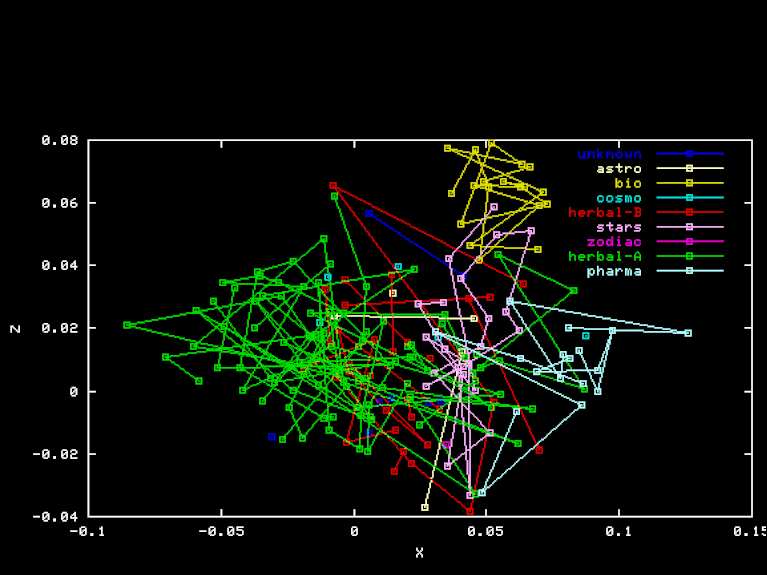
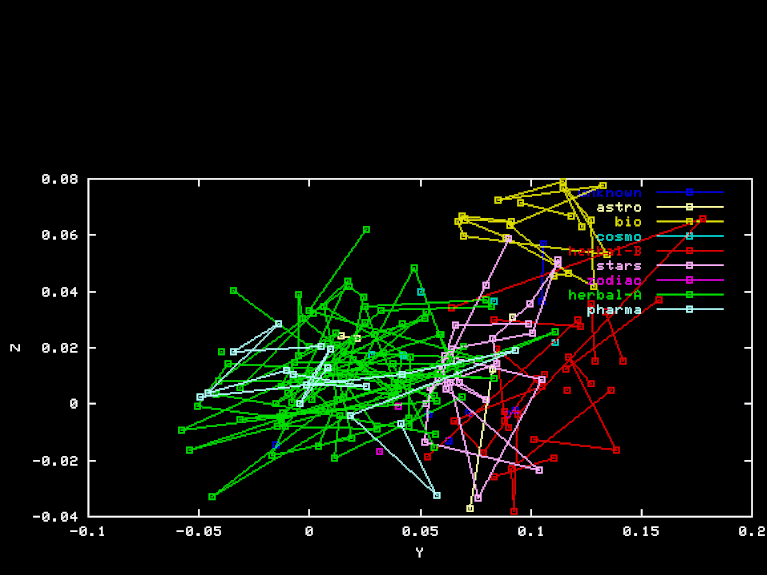
The initial coordinates of each page are the relative frequencies of these elements in that page. To produce the plots, I picked three mutually orthogonal unit-length vectors X, Y, and Z, in 50-dimensional element frequency space, and projected the page points onto them.
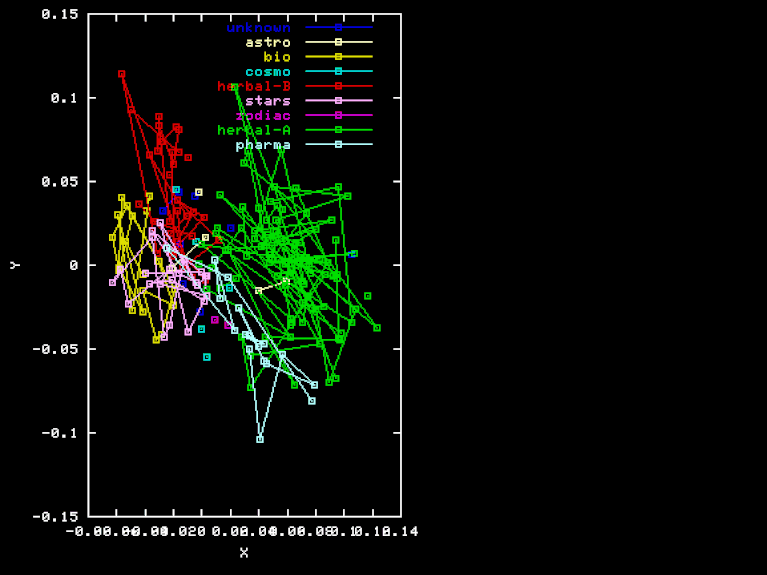
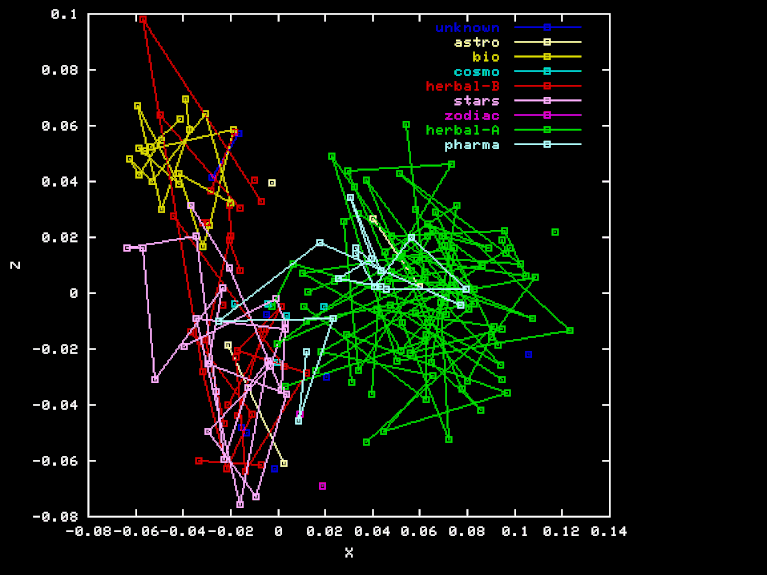
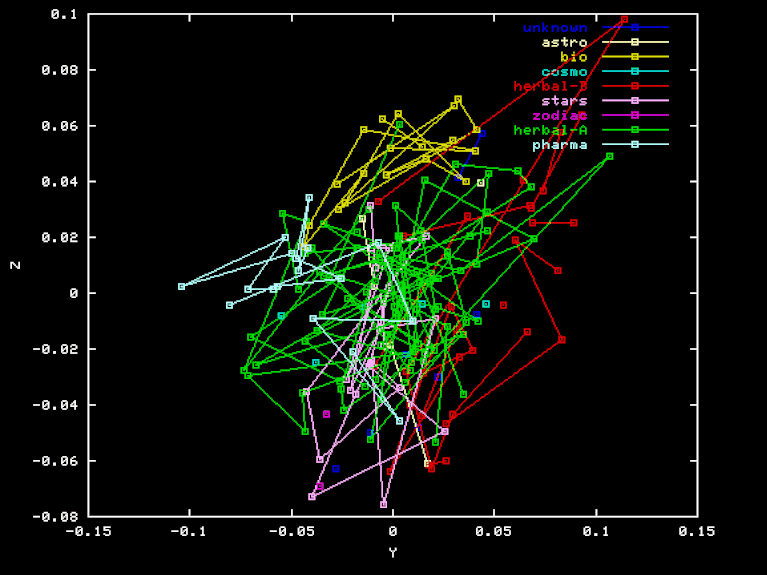
For the "Herbal" projection, the X, Y, and Z axes are the result of Gram-Schmidt orthogonalization applied to the vectors HEA-TOT, HEB-TOT BIO-TOT, where TOT is the vector of element frequencies for the whole sample, and HEA, HEB and BIO are the frequencies for the Herbal-A, Herbal-B, and biological sections, respectively. Here are the X, Y, and Z coordinates of each page in this projection.
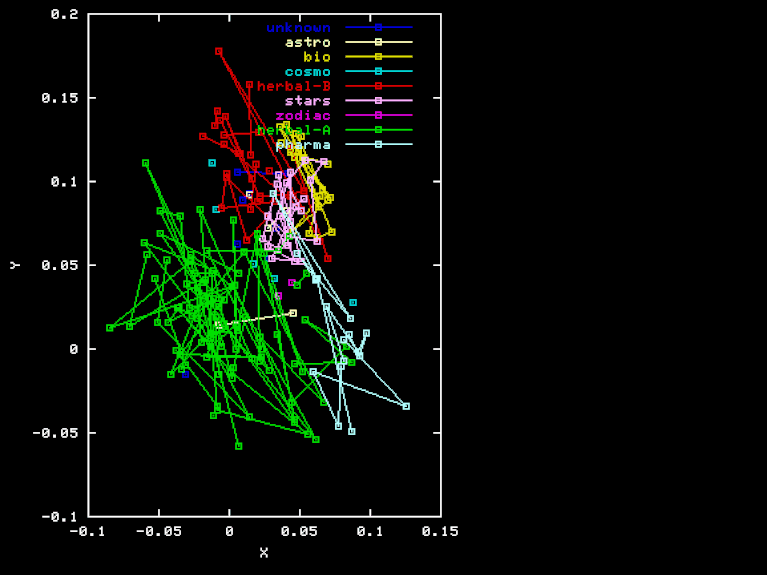
The "Pharma" projection is an attempt to discover a separation of Herbal-A pages from Pharma page, by using a different projection to three-space. The X, Y, and Z axes were obtained by orthogonalization of PHA-HEA, HEB-HEA BIO-HEA, where PHA is the vector of element frequencies for the "Pharma" section. Here are the X, Y, and Z coordinates of each page in this projection.
You may want to check another version of these plots where similar characters have been identified.