



|
|
|
|
|
Labels appear in the Voynich MS in several places. In the zodiac illustrations, essentially every degree of each sign has a female figure holding a star, with a word written near it. This word (rarely also more than one word) will be referred to here are a 'zodiac label'. A second specific set of labels appears near small plant drawings in the so-called pharmaceutical section of the MS. These will be called 'pharma labels' (1).
Further examples are labels near stars on so-called astronomical pages and labels in the so-called biological pages. Most of our attention in the following will go to the zodiac labels. As only 10 of 12 signs have been preserved in the MS, there should be 300 such labels, but, presumably due to a mistake by the author(s)/scribe(s), one is missing so we only have 299.
In total, 1029 labels have been identified in the MS, but a number of these are single words or characters that are not near drawing elements. Some of these are part of sequences of words or characters. These will not be considered in this study. It is tempting to think of labels as names, or at least nouns, but this may not necessarily be the case. Labels may be adjectives, or in the case of the zodiac even numbers or coordinates. We will do our analysis without making any such assumptions.
The analysis is based on a transliteration of the Voynich MS text: the Reference Transliteration version 1b, as provided using the Basic Eva character set (link to file). This file includes a number of so-called ‘uncertain spaces’, which are represented by a comma. In the following analysis, these are always ignored (considered not to represent a space). The 299 zodiac labels have been collected in a single text file. A few labels consist of two or three words, and these have been treated as a single label (including spaces, which are represented by a period). The first 30 labels are shown below, using the Eva transliteration alphabet.
otalalg okody otaral okasy opysam otalar otar? chckhhy otalam oty otaly dolaram oky.ody otal.arar okaram oty.ar otaldy oteosal okaly okeoly salols otody okydy okaldal otald okees ykolaiin otaldar atar.am otolal
Some aspects of these labels have already been commented on in the past:
The main reason for this mini-study is to test this third qualitative observation with quantitative data.
The 30 most frequent zodiac labels are shown below. The last four already appear only once, and this is true for all other zodiac labels (2). A word that appears only once in a text corpus is called a "hapax legomenon", which, for convenience, will just be called "hapax" in the following.
5 otaly 2 otalaiin 2 okaram 5 okal 2 otal 2 okaldy 4 okaly 2 okydy 2 okalar 3 okeody 2 oky 2 oeeodaiin 2 ykey 2 okeos 2 oeedy 2 ykeedy 2 okeoly 2 cheoldy 2 oty 2 okeey.ary 1 ytoar.shar 2 oteody 2 okeey 1 yteody 2 otaraldy 2 okeeody 1 yteod 2 otaldar 2 okedy 1 yteeody
Other terms that will be used frequently are "word token" and "word type". A text of 200 words includes 200 word tokens. Since typically some words will appear more than once, this text may have only 150 different words, or 150 word types.
The above distribution of label words could be shown graphically, but this graph will be relatively non-distinct. Instead, we can summarise it with two parameters: the frequency of the most common word type and the percentage of hapax. The latter is computed as the number of hapax divided by the number of word tokens.
These numbers are correlated with each other to some extent, but they can vary independently. A third parameter that has been used in this context is the number of word types divided by the number of word tokens (type-token ratio or TTR). This has been used in studies using MATTR (moving average TTR), which did not concentrate on the labels, but have their own interest (3).
The most frequent word type among zodiac labels appears 5 times. The number of hapax in the zodiac labels is 238, leading to a hapax-% of 80%. In order to decide if this distribution is unusual, we need to compare these two numbers with other groups of 299 words in the MS. Since 299 is a relatively small sample of words, we may expect that the count of most frequent words is subject to aribitrary variations. For that reason, we may regularise the most frequent word count by using a weighted average of the three most frequent words. These weights are set to 3/6, 2/6 and 1/6 for words 1-3 respectively.
The first set of words for comparison is taken from the circular texts of the zodiac pages. These may be expected to be most similar to the labels. These texts have not received much attention in Voynich MS text studies. The concatenation of these circular texts has 910 word tokens, which allows us to extract three groups of 299 words. These have been chosen to be words 1-299, 301-599 and 601-899 respectively (4). The relevant statistics for these three groups (called Cz-A, Cz-B and Cz-C) are shown in Table 1, together with the average of the three.
| Text group | Freq.word | Weighted | Hapax-% |
|---|---|---|---|
| Cz-A | 10 | 9.2 | 63% |
| Cz-B | 10 | 8.0 | 58% |
| Cz-C | 6 | 5.5 | 73% |
| Cz (avg) | 8.7 | 7.6 | 65% |
| Labels | 5 | 4.8 | 80% |
Table 1: frequency distribution parameters for circular texts in the zodiac,
compared with the zodiac labels
A 'flat' distribution is characterised by a relatively low count on the most frequent word, and a high hapax percentage. All three groups have a distribution that is less 'flat' than the zodiac labels, though the third comes reasonably close. This last point may warrant a closer look. The average of the three groups is quite distinct from the statistics of the labels.
A second comparison text of interest is provided by the so-called recipes or stars section in quire 20 of the MS (5). Here, each page has more than 299 word tokens, so the first 299 words of each page can be compared with the zodiac labels. The results are shown in Table 2.
| Text group | Freq.word | Weighted | Hapax-% | Text group | Freq.word | Weighted | Hapax-% |
|---|---|---|---|---|---|---|---|
| f103r | 11 | 10.3 | 64% | f103v | 13 | 10.8 | 49% |
| f104r | 6 | 6.0 | 63% | f104v | 9 | 7.5 | 57% |
| f105r | 6 | 5.8 | 65% | f105v | 11 | 9.5 | 63% |
| f106r | 7 | 6.7 | 66% | f106v | 8 | 7.2 | 67% |
| f107r | 10 | 8.5 | 65% | f107v | 9 | 8.5 | 50% |
| f108r | 9 | 8.3 | 54% | f108v | 9 | 8.3 | 53% |
| f111r | 12 | 9.5 | 56% | f111v | 15 | 11.7 | 44% |
| f112r | 11 | 9.3 | 56% | f112v | 12 | 9.8 | 51% |
| f113r | 8 | 6.5 | 69% | f113v | 11 | 10.0 | 63% |
| f114r | 8 | 7.0 | 67% | f114v | 8 | 7.5 | 63% |
| f115r | 9 | 7.5 | 59% | f115v | 6 | 5.0 | 70% |
| f116r | 12 | 10.3 | 42% | f116v | - | - | - |
| Avg page | 9.6 | 8.3 | 59% | ||||
| Labels | 5 | 4.8 | 80% | ||||
Table 2: frequency distribution parameters for text in quire 20,
compared with the zodiac labels
We see that the weighted most frequent word ranges from 5.0 to 11.7, while the zodiac labels are at 4.8. The average of these pages is 8.3, slightly higher also than the circular texts on the zodiac pages. The hapax-% ranges from 42% to 70%, while the zodiac labels are at 80%. The average of the stars pages is 59%, lower than the circular texts on the zodiac pages. Again, one page comes somewhat close to the statistics of the zodiac labels, at least for its first 299 words, and also this may warrant a closer look. For the average, the differences with the zodiac labels are significant.
The other parts of the Voynich MS text are also tested, but not to their full extent. They are summarised in Table 3. For the word count, only text in paragraphs (or along circles in one case) is included. When the individual pages of a particular area are not long enough to provide 299 word tokens, these sections are concatenated, and the total number of words is indicated in the Table.
| Text | Selection method | Nr. of words | Samples |
|---|---|---|---|
| Herbal-A | Concatenation of short pages | 7669 | 6 |
| Herbal-B | Concatenation of short pages | 3378 | 6 |
| Pharmaceutical | Concatenation of short pages | 2287 | 6 |
| Biological | Use individual pages | - | 6 |
| Astro-Cosmo circles | Concatenation of circles | 1187 | 3 |
| f58 r+v | Use individual pages | - | 2 |
Table 3: Further text samples for analysis
For each group of concatenated pages, up to six 299-word samples are taken in exactly the same manner as described for the zodiac circular text above. For the biological pages and f58r, f58v, the first 299 words of each page are used.
The individual samples are not listed, but they have all been included in Figure 1 below. This shows the weighted count of the most frequent word along the X-axis and the hapax-% along the Y-axis.
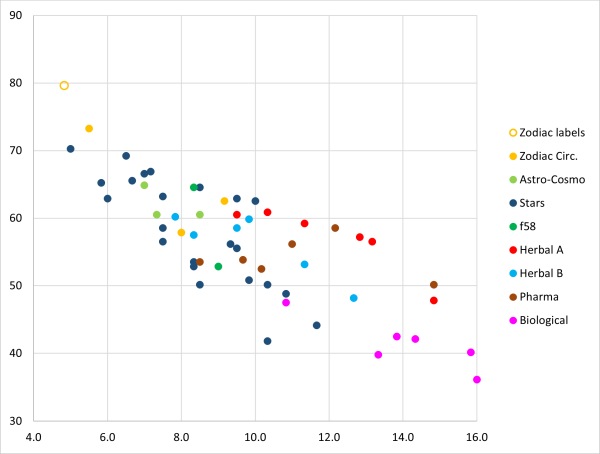
Figure 1: Statistics of individual samples of 299 word tokens
The zodiac labels are clearly separated from the running texts in terms of hapax-%. In extreme cases, the most frequent word count (weighted) can come close to that of the labels case, but the spread in this quantity is quite large. It turns out that, indeed, the zodiac circles and the stars text of quire 20 do come closest to the zodiac labels, based on these statistics.
The averages per section are listed in Table 4 (also including the earlier results), and shown in Figure 2.
| Text group | Freq.word | Weighted | Hapax-% |
|---|---|---|---|
| Zodiac Labels | 5 | 4.8 | 80% |
| Zodiac circles average | 8.7 | 7.6 | 65% |
| Astro/Cosmo average | 8.7 | 7.6 | 62% |
| Stars average | 9.6 | 8.3 | 59% |
| f58 average | 10.5 | 8.7 | 59% |
| Herbal-A average | 14.0 | 12.0 | 57% |
| Herbal-B average | 10.8 | 9.9 | 56% |
| Pharma average | 14.3 | 11.1 | 54% |
| Biological average | 15.8 | 14.0 | 42% |
Table 4: Statistics for averages of 299-word samples
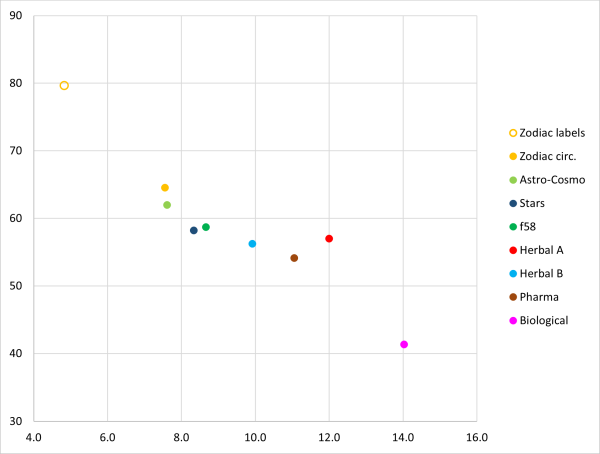
Figure 2: Statistics for averages of 299-word samples
For these averages, the difference between running text (also when along circles) and labels is very clear and significant. Before looking more deeply into these results, let us also analyse the Pharma labels.
On the three pharmaceutical bifolios, labels appear near plant fragments and near containers. For this analysis both types are included. Based on this, there is a total of 234 labels, a little less than the number of zodiac labels (6). The most frequent label words are listed below (see note 2).
3 otoldy 2 otaly 1 yteoldy 3 otaldy 2 otal 1 yteold 2 sary 2 oky 1 ytchol 2 otory 2 okol 1 ytasem 2 otoram 2 okeody 1 ytal 2 otoky 2 okary 1 ypcholdy
In this case, already the 13th word type is a hapax. The most frequent word appears 3 times, and the weighted count is 2.8 . The hapax percentage is 89%. These numbers are even more indicative of a flat distribution than the zodiac labels, but for a fair comparison, we should also compute them for the first 234 zodiac labels. These numbers are collected in Table 5.
| Text group | Freq.word | Weighted | Hapax-% |
|---|---|---|---|
| 299 zodiac labels | 5 | 4.8 | 80% |
| 234 pharma labels | 3 | 2.8 | 89% |
| 234 zodiac labels | 4 | 3.5 | 85% |
Table 5: Statistics related to the pharma labels
The numbers for 234 pharma labels and 234 zodiac labels are relatively close, where the pharma labels are marginally more 'flat', but it is hard to say whether this difference is significant or not. In any case, it will not be necessary to do more comparisons with the other texts. Both sets of labels have a flat frequency distribution that is very different from the running text.
Not only is the frequency distribution of label words different from the main text, also its vocabulary is distinct. While many if not most label words do appear in the running text, the most common words in the running text do not appear as labels. It appears as if the label words form a specific subset of the Voynich MS text, but this remains to be investigated in more detail.
Just for the sake of convenience, here we will only look at the distribution of word-initial character pairs for various different parts of the text, when these words are expressed in Eva.
We had already seen from the short word lists above, that label words frequently start with "ok" or "ot". For the zodiac labels, these two cover 52% of all word tokens and for the pharma labels 32%. More detailed distributions are shown below, as pie charts in figures 3a,b (for the labels) and 4a,b (for running text: herbal-A and stars).
The colour scheme is kept consistent for the four cases: light and medium blue for "ot" and "ok", yellow for "qo", light orange for "da", red for "ch", dark orange for "sh" etc. Grey means: "all the rest".
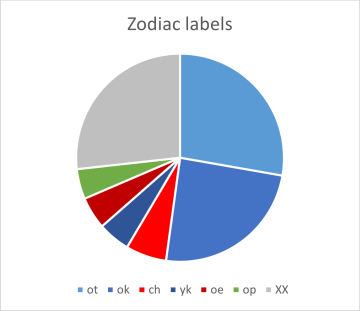
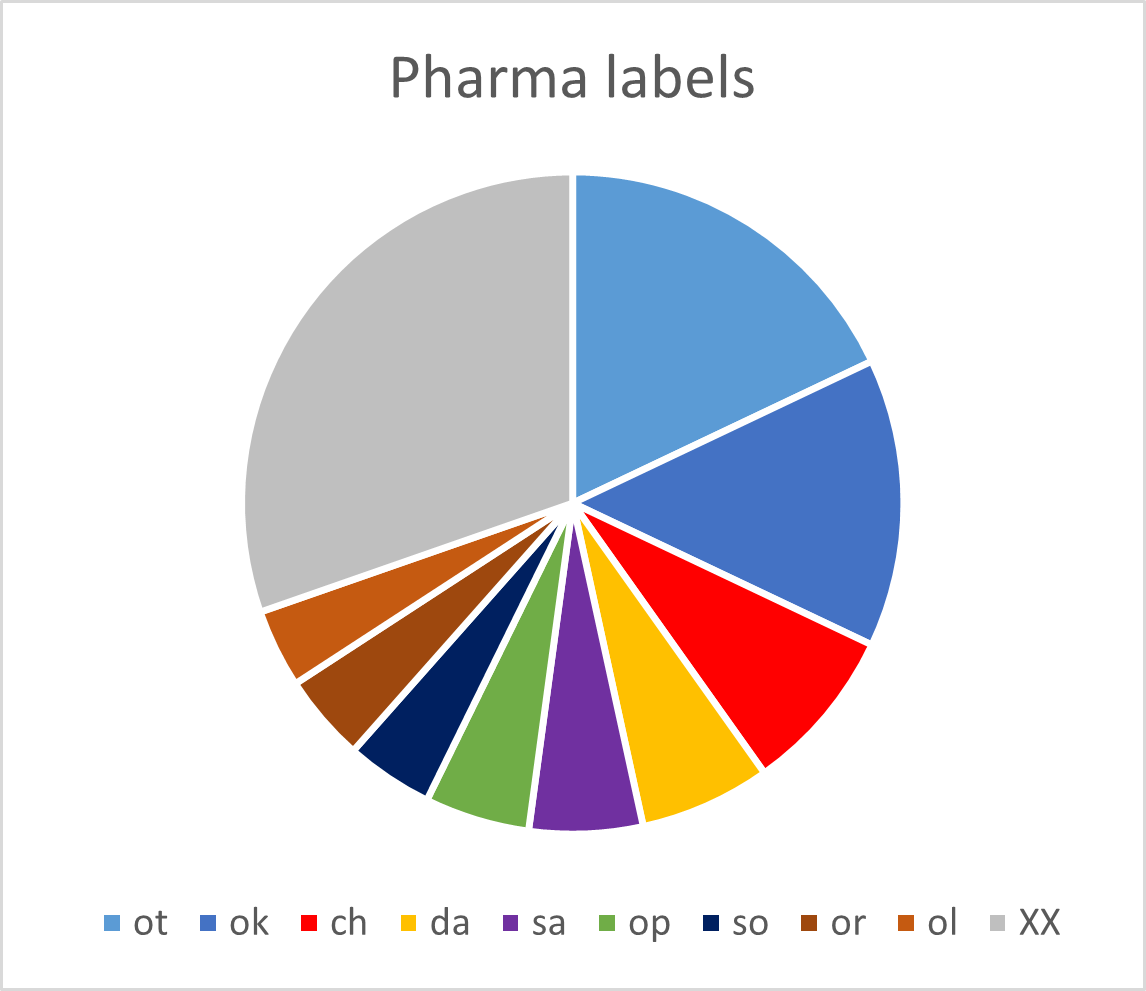
Figure 3a,b: distribution of word-initial character pairs for labels
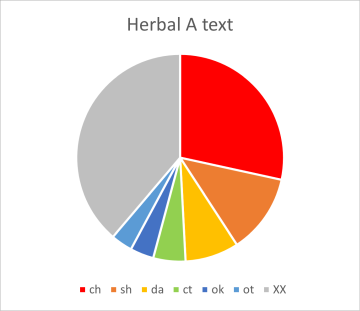
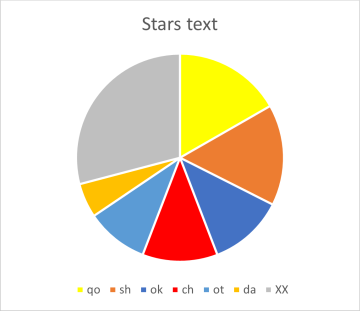
Figure 4a,b: distribution of word-initial character pairs for running text
The majority of words both in the herbal A text and the stars texts start with character pairs that are barely represented in the labels. Much more could be said and analysed about this topic, but we will limit ourselves here to this short but very clear example.
The two sets of labels appear similar, at least with respect to their word-initial character pairs, but it is worth checking in more detail whether they also include the same word types. This would not be expected in case the zodiac labels represent zodiac-related terms while the pharma labels represent herb-related terms.
The combined list of zodiac and pharma labels includes 532 word tokens (299 + 233), 469 word types and has 428 hapax. The maximum number of hapax would have been the sum of 238 and 207 = 445. Following is the complete list of label words that appear as a label both in the zodiac and in the pharma pages. The numbers after the word indicate how frequent they are among the zodiac and pharma labels respectively. The ones preceded by an asterisk (*) were hapax in either list.
otaly 5 2 okeody 3 2 otal 2 2 * okaiin 1 1 * okary 1 2 * okeeos 1 1 * okeoly 2 1 * okody 1 1 * osary 1 1 * otalam 1 1 * otaldy 1 3 * otary 1 1 * otoly 1 1
This shows that only 13 word types appear in both sets, and only 10 hapax are no longer hapax (7).
Figures 1 and 2 above show a relationship between two parameters that characterise the flatness or steepness of a frequency distribution: weighted most frequent word and hapax-%. To provide more context for these numbers, they have also been computed for a few known texts. These are listed in Table 6 below.
The texts have been converted to a single case, and all interpunction and arabic numerals have been removed. Roman numerals appear in some of these texts and are kept. Six chunks of 299 word tokens have been taken from each text, and their average properties are shown in Table 6 below (8).
| Text | Century | Language | Freq.word | Weighted | Hapax-% |
|---|---|---|---|---|---|
| Alchemical herbal | 14 | Latin, vulgar | 29.8 | 19.9 | 36% |
| Dante: Inferno | 14 | Italian | 15.2 | 13.3 | 48% |
| Karel ende Elegast | 13 | Middle Dutch | 14.7 | 12.9 | 46% |
| Pliny the Elder | 1 | Classical Latin | 10.5 | 8.7 | 67% |
Table 6: Statistics for some known texts
They are also included in Figure 5 using open squares, together with the points for the various parts of Voynich MS text.
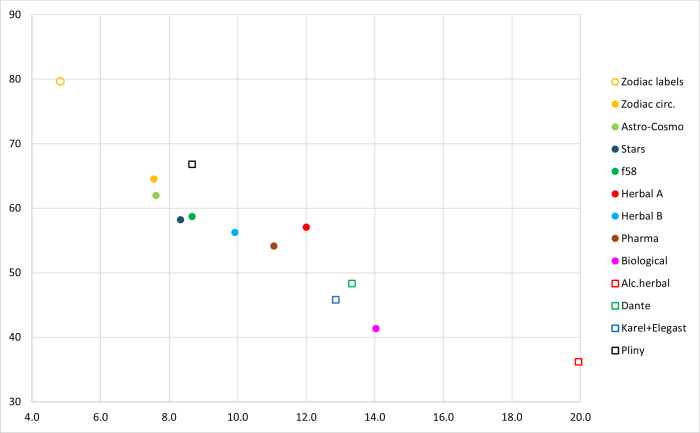
Figure 5: Combined Voynich MS and known-text statistics
The alchemical herbal text includes several recipes that tend to use rather similar descriptions, and this text has an even steeper word frequency distribution (for the short 299-word samples) than Voynich biological.
The two texts: Dante's "inferno" and "Karel ende Elegast" are narratives, and their properties are similar. Compared with the Voynich MS, they lie beween the biological and herbal pages. Both the Middle Dutch and Italian languages use inflection for verbs.
Pliny's "Natural history" is an encyclopedic text, and is written in the even more inflected classical Latin. As a result it has a much flatter distribution, similar to the Voynich stars section but with a slightly higher hapax percentage (see Figure 2).
Overall, this shows that the parameters that have been observed for the Voynich running text generally coincide with the known texts, while the labels are still outliers.
People have long been familiar with Currier languages (A and B) in the MS. In recent years I have proposed a refinement, where, first of all, a third main language is defined (C) and, secondly, several dialect and variants have been added. This is explained in detail on this web page.
Looking at that web page, we see that the zodiac labels are on MS pages whose language type is Ce- (based on the circular texts) and the labels themselves are also Ce-. This means that both sets have a relatively high percentage of the character combination "eo", and are low in initial "qo".
The pharma labels are on pages whose language type is Ae, meaning a relatively high percentage of the character combination "eo" and a moderate occurrence of initial "qo". The pharma labels are language type A-, meaning low occurrence of "eo" and of initial "qo". In that respect the pharma labels are different from the main text surrounding them, but also from the zodiac labels.
The meaning or consequence of this is not clear, but there is another language-related aspect that is more surprising. Figure 2 is repeated below as Figure 6, but with an indication of the 'main' RZ language type of each average point. The figure does not include a point for the pharma labels, because this does not exist (we do not have 299 pharma labels). Had it existed, it would have been close to the zodiac labels, and have an arrow pointing to it from "A".
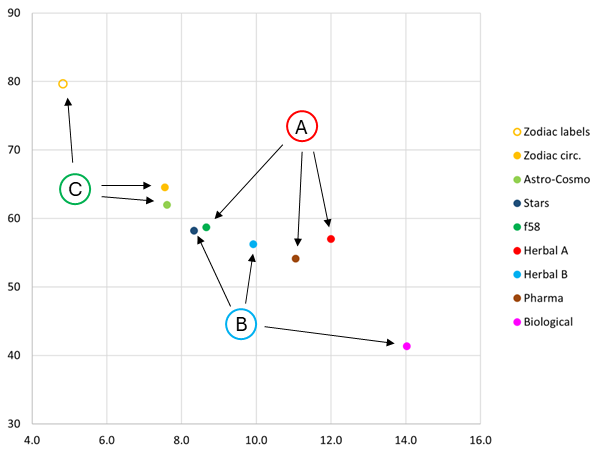
Figure 6: main 'RZ' languages of the average page statistics
The most remarkable aspect is that the distribution of the points representing the averages is not at all correlated with the language of the page. A and B languages are arbitrarily mixed. Equally surprisingly, there appears to be a correlation with the illustration type:
These observations are not related to the main topic of this page, but they are quite unexpected and absolutely warrant a closer look.
We have seen that the zodiac and pharma labels in the Voynich MS have entirely different properties from the main, running text in the MS. They do not include any of the most common words in the MS, and their frequency distribution is almost flat. They are not all different, but they are close to that.
This is an important result, when judging the meaning of the text in the Voynich MS. It is certainly not the result of chance, or some arbitrary process in the generation of the text by the MS creator(s). It is without any doubt the result of some purposeful action.
I do not intend to argue that this implies that the text is meaningful. This is not yet proven by any means. However, the observed behaviour is fully compatible with the case that the MS contains a meaningful text, and it is hard to explain in most scenarios where the text is proposed to be meaningless.
While it is not difficult to present arguments why the text could or should be meaningless, we have not seen many proposed methods how such a meaningless text would have been created. The best known examples of such methods are Gordon Rugg's moving grille, and Torsten Timm's auto-copy method. Any method to create meaningless text would have to include dedicated rules or actions just for the generation of labels, in order to deliberately achieve their unusual properties. For the two named examples, which both rely on some arbitrary actions of the creator, it is not clear to me how the two features: a selective vocabulary and a flat frequency distribution, could even be achieved.
More in general, with the text already being unreadable, there would hardly appear to be any need.
I therefore contend that the balance should be a bit more in favour of the hypothesis that the contents of the MS are meaningful.
|
|
|
|
|