








|
|
|
|
|
|
|
|
|
|
This page, which will become the last page in the 'main sequence' of pages, is still in the process of being written. In its final form, it will be a summary of several topics that are elaborated on a number of much more detailed pages.
An explanation of the Voynich MS text needs to take into account all features and aspects of this text. In the discussion of each of the topics, no attempt will therefore be made to come to any conclusion. The purpose in each case is to highlight pros and cons, and where possible to eliminate some options.
It is clear that the main unanswered question about the Voynich MS is: "what does it say?". At the same time one can ask: "why has nobody found the solution yet?". Does this mean that the MS could be meaningless after all? Or has someone already found the solution and we simply haven't realised it? Or, alternatively, has everyone been looking in the wrong direction for the last 100 years?
A significant amount of statistical analyses have been performed, and many features of the text have been observed and reported. A (still very incomplete) summary of these is presented in the text analysis section. This section is equally in the process of being updated and extended.
My argument here is that a good approach to finding the explanation of the MS text requires taking into account the combination of all available evidence, which consists of a large corpus of evidence, conclusions, statements, assumptions, opinions, facts, theories, etc. etc., and the true explanation of the Voynich MS text has to fit all of them in the appropriate manner. That means:
When that has been achieved, this true explanation is then capable of telling us which assumptions, opinions, theories, etc. were correct and which were not.
Clearly, it is of critical importance to correctly classify all statements one may find about the Voynich MS into the different categories of:
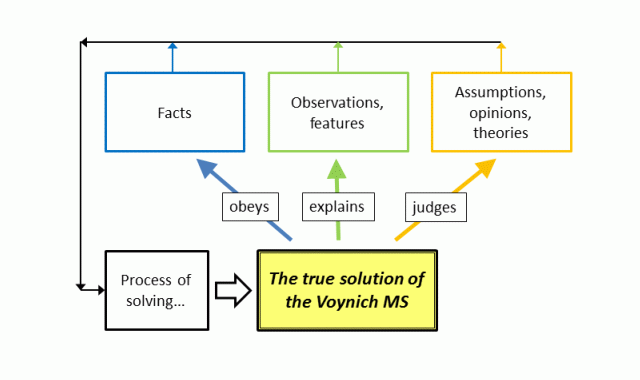
It is not only important to be critical about what we know, but also important to keep in mind what we specifically don't know. Most of the factual information we have about the MS concerns the materials it has been made of. There are also some obvious facts, the importance of which is easily overlooked.
The parchment of the MS has been radio-carbon dated and gives a consistent time frame when this parchment was prepared. What we don't know anything about is how long the conception and creation of the MS took. This entire process may have taken anywhere between just a few years and, say, thirty years (1), and we don't know if it involved creating a complete draft before making the copy we have, nor do we know at which point in the process the parchment was acquired by the author. It may also have been acquired in batches. The radio-carbon dating of the individual sheets is not precise enough to tell us this.
The conception of the MS may already have taken place during the later part of the 14th Century, while the completion of the MS may also have been as late as ~1450. The handwriting on the last page (f116v), which should coincide with the completion of the MS, or could also be a later addition, is not to be dated after the 15th Century, though.
While everything points to the MS having been created in Central or Southern Europe, nothing should be assumed about the language used for the text (if there is a plain language meaning at all, of course). In fact, it may well be that assumptions that the language should be Latin or one of the main vernaculars in 15th C Europe has contributed to the failure in interpreting the text until now.
It is a fact that no other contemporary document survives that uses the script of the Voynich MS. This has been taken as evidence that the script was specifically created for this occasion. This may well be so, but it is not clear that this makes a big difference for the study of it.
Another important fact is that a consistent character set is used throughout the MS, from the beginning till the end. The same is true for parts of the vocabulary. Many frequent words occur throughout the MS, from the beginning till the end. Therefore, we can state that the entire conception of the MS was a carefully planned and executed activity. It is also true that there are some variations. The meaning of these variations is subject to interpretation.
Counts of the number of different characters that occur one than once in the text has resulted in values between (roughly) 24 and 36. Even if that range is rather wide, it is clear that the script is an alphabetic one. It could be an abjad, in the sense that vowels may not be represented, or only in some cases, though not in the sense that consonants and vowels are combined into composite characters (2). It has to be stressed that this is a property of the script, not the language, and it should not be assumed that the language has to be one that is usually written in an alphabetic manner (again, assuming that there is a plain text language in the first place).
This is quite a short list of facts, and I cannot think of anything else right now. Many of the well known observations about the text of the MS are (or should be) listed under 'features' below.
Many features of the text have been observed and reported, and a summary of them is presented (3) in the text analysis section, without intending to claim completeness. Some of these features are quite pronounced, and any proposed solution needs to account for, and be able to explain all of them. Following is a list of what I believe are the most important ones.
Now it is tempting to try and find possible explanations for each of these features. For most of them it is not even difficult, with the notable exception of the word structure. (In fact, finding a good explanation for this point should take one a big step closer to a possible explanation of the Voynich MS text. We will come back to this further below.)
The key point to make at this stage, however, is that the vast majority of solutions that have been proposed so far do not even attempt to explain any of these features, and I am not aware of any example that addresses all of them.
Specifically, when a proposed solution includes an alphabet table in which p and f are simply mapped to a plain text character of the alphabet, one can be certain that this solution is incorrect (4).
The text exhibits a number of features that suggest it should be language-like or meaningful. Some can be expressed quantitatively, others not. The problem is that none of this evidence is very strong. Zipf's law is followed, there are long-range correlations which are destroyed when the text is scrambled, and there is some numerical correlation between the text properties and the section of the MS. All of these need to be explained in case one proposes a method whereby the MS text is not meaningful, but was instead created using some arbitrary process.
There is one specific feature that needs to be highlighted here. While the many body of the text follows Zipf's law, this is not true for the labels. Specifically for the zodiac labels, the word frequency distribution is almost flat. Some labels do occur up to four times, but the vast majority is unique, and the frequency curve for these words is highly anomalous for a peice of text. It is therefore certain that these labels are 'something different' from the main text. This is again evidence that the text creator (author) was working with a purpose.
The Voynich MS written text shows almost no corrections or erasures. This has been interpreted by some to indicate that the scribe could actually not understand what he wrote, or even that the text was meaningless, but this is not necessarily true. In any case, this is a type of feature that a proposed solution does not need to 'explain'. However, it is a feature one should keep in mind when defining statistical tests, or even a proposed solution. One thing it could mean is that the text has a significant number of errors (since they were not corrected). More in general, one needs to keep in mind that the text, even if it is meaningful, may have significant spelling variations. Comparisons with known plain texts will be biased because of this, as such reference texts are most commonly following a clearly defined orthography and have been fully spell-checked.
Following is the (still very short) list of topics that are addressed in the course of this page.
In each case, the discussion in the present page is a summary of a longer page dedicated to each topic. Links are provided.
On this page I already argued that at least the most common solution approach, namely finding a way to translate the text of the Voynich MS back to plain text, is fundamentally wrong. It could work, but only if several implied assumptions are all valid. The most obvious, but also most commonly ignored assumption is that the MS includes a meaningful text, ideally in a language that we still understand. Now I have read and heard many times that, clearly, it wouldn't make sense for such a long MS to be meaningless so there has to be a possible translation. Even though that seems to make sense, it is an assumption, and several scenarios have already been proposed in which it would make sense for someone with a lot of spare time and some means, to create a meaningless book, 600 years ago.
Let us therefore create a top-down tree structure of possibilities for the meaning of the MS. This has been elaborated in detail on a separate page, in the form of a list of multiple-choice questions, and it is summarised here.
 |
Classification of solutions |
Let me start by repeating a key phrase from this page:
We don't yet know whether the Voynich MS represents a meaningful text. What we do know for certain, however, is that some time in the past, somebody or some group of people sat down and wrote the Voynich MS using some method. [...] Unfortunately, we don't (yet) know this method. We can only imagine a multitude of different ways how it could have been created.
This text generation method is what we should be looking for, and in the following I will classify some high-level aspects of it using a tree structure. We will then see in which cases the usual 'decoding attempts' could be valid and in which cases they cannot lead to success.
At various points in the tree structure for the text generation method there are different options. All of these options are numbered. In the detailed description I will not go into the question of the likelihood that one or the other option is correct. It is necessary to keep this completely open at this stage. Instead, in the more detailed description I will give what I call examples and challenges.
Examples are ways how a particular option could be explained, without aiming for completeness. They are just there to show that one should not discard any option off-hand. They are summarised on the present page.
Challenges are points that might not be easy to explain in case a particular option is chosen. They are not included here.
The total ensemble of all possible solutions is what I called the solution space in the previous page, and it is represented by the entire tree structure developed below. The tree is developed primarily along the branch of meaningful solutions. The other branches are more difficult to develop.
Whether the text still has a recoverable meaning is addressed as a combination of two different questions. Question 1 is: what did the author intend 600 years ago. Question 2 is: in case he wrote something meaningful, can we still extract this meaning 600 years later?
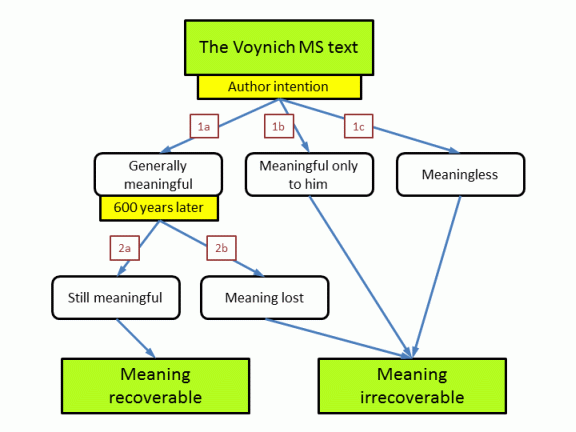
Question 1: was it originally meaningful or not?
Option 1a: the author 'encoded' something meaningful
This is the most easily understandable option, and the one that most people tend to assume automatically. The text would be written in any known language of the 15th Century, either well known or more exotic, and represented in a strange alphabet, possibly with some cryptography added as well.
Option 1b: the author 'encoded' something that was meaningful only to him
To explain this option, let's just look at f116v of the Voynich MS. This has text written mostly in plain Roman characters. It is quite possible that this was written by the original MS composer/author. However, it has not been possible so far to make complete sense of it. Now what if the entire MS contains text similar to this? People decoding the text would not even recognise that they solved it, even if they did. Numerous other manuscripts exist that include some magical and nowadays basically meaningless text.
Option 1c: the author intentionally created something that has no meaning
While the exact method given by Gordon Rugg does not work, the idea he proposes is a good example in general how this could be done with 15th Century means. Other methods could include generating / picking words from an existing text that has been written in a language or script unknown to the author.
Question 2: was the meaning lost over time?
This question further qualifies the case 1a above, that the original author intended to write something generally understandable. The question is whether this meaning is still recoverable now. The boundary between 'yes' and 'no' may not be very precise.
Option 2a: meaning still recoverable
Again, this is the most easily understandable option, and the one that most people tend to assume automatically. 'Recoverable' should be understood as 'in principle'. It should not necessarily be easy.
Option 2b: meaning no longer recoverable
The loss of the original meaning would happen, for example, in case a meaningful text has been encoded using an irreversible method. A variation of this is the so-called 'ignorant scribe' scenario, where a scribe unintentionally makes an inaccurate copy of the original, thereby eliminating critical information or introducing large errors. Another possibility is in case the original language is no longer known.
Questions 1 and 2 summary
In the end we have two options: either there is a recoverable meaning or there is not. In the negative case, we have identified three high-level possibilities how this could have happened.
Question 3: are word spaces significant?
We are now ready to further explore the case where the MS text still has a recoverable meaning, and one of the first questions that arises is related to the spaces we see between groups of characters. In the analysis section we called these groups of characters 'word tokens'. Here, for brevity, I will just call them 'words'. The question is whether the spaces are really meant in the sense that these character groups indeed represent words, which is something that most people will almost automatically assume.
Also this question is addressed as a combination of two different questions. Question 3 is: are the word spaces as we see them real separators between units of information. Question 4 is: in case not, can we still (re-)introduce such spaces / separators in a (more-or-less) simple manner?
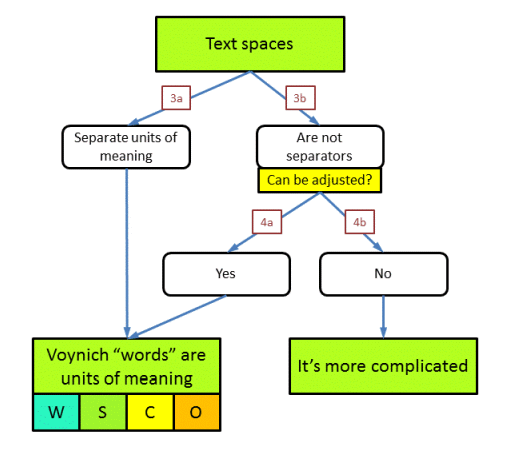
Option 3a: word spaces are significant
This is the most easily understandable option, and the one that many if not most people tend to assume.
Option 3b: word spaces are not meant as separators
In this case there are several possibilities. It could be that some spaces are 'real' while others are dictated by orthography, as in the arabic script where there are breaks following characters that cannot be 'connected' to the next one. In the other case, spaces could be completely arbitrary.
Question 4: can we figure out word spaces anyway?
This question further qualifies the case 3b above, that the spaces we see in the Voynich MS are not (always) word separators.
Option 4a: there should be word spaces and they can be (re-)introduced
This is only likely to be possible if some large part of the spaces we see in the MS is real. Another option would be that word spaces are to be ignored altogether, and another character is meant as a word separator.
Option 4b: it is not possible to (re-)introduce word spaces
This option just confirms the idea that word spaces are completely arbitrary, and it is not possible with easy means to identify the real ones.
Questions 3 and 4 summary
In the end we have two options: either we can identify the words in the text with 'units of meaning', or we cannot. Beside the examples given above, the negative case could also arise in very different scenarios, for example that the text as we see it is not meaningful text but more like a 'background', against which we need to extract the real meaning from geometrical means, or by selecting individual characters using a grid, etc. etc.
The units of meaning could represent (in the plain text) words, syllables, characters, or other, as indicated by the codes W, S, C, O in the above figure.
Question 5: is a word-for-word translation possible?
Having reached a point in the tree where the written words in the MS are representing units of meaning, the next logical question is, whether each word type we see in the MS is a consistent rendering of the same unit of meaning in the original or plain text. The easiest case would be if one plain text word would be uniquely represented by one word in Voynichese, i.e. there is a one-to-one mapping. Another possibility would be that a plaintext word is represented by different Voynichese words (one-to-many). As long as each Voynichese word derives from only one original plain text word, we would still be able (in principle) to reverse this process and retrieve the plain text. A third possibility is a many-to-one mapping. Here, several different plain text words would map onto the same Voynichese word. This is in principle irreversible (5).
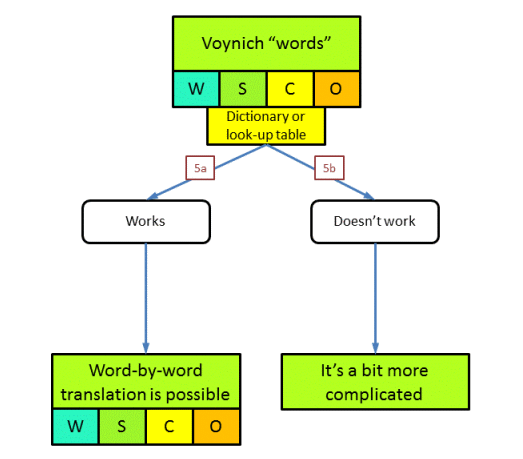
Option 5a: there is a one-to-one or one-to-many mapping of plain text to Voynichese
To deal with this question, we should imagine that there exists a 'dictonary' from plain text to Voynichese. It is not necessary that this dictionary physically exists. In the one-to-one mapping case, this dictionary has one entry for every plain text word, and it translates to one Voynichese word. If we had this dictionary, we could translate the text back.
The one-to-many mapping means that our (imaginary) dictionary has one entry for each plain text word, and this can translate to several different Voynichse words. If we had this dictionary, we could still translate the text back, assuming that there is no overlap in the Voynichese words from different plain text words. (In that case we should call it a many-to-many mapping). One possibility for ending up in such a situation is in case the author encrypted the text using a poly-aphabetic cipher, or added null characters.
Option 5b: there is no (clear) mapping from plain text to Voynichese words
This situation could arise if the text is a very inaccurate rendering of an 'unusual' language, with loss of unique representation (several sounds mapping to the same character). It could also be that a cipher has been used that maps many to one. Finally, the text could include a great number of mistakes.
Question 5 summary
At the end of this question we end up with basically two options. Either the text that we have in the Voynich MS could be translated back to a plain text using a consistent word-for-word substitution, or it cannot.
Question 6: does the word 'dictionary' have a system?
We have now reached the point where there exists (in theory) a dictionary that would allow a word for word translation of a plain text into Voynichese and vice versa. We may compare the plain text words and the Voynichese words, and see if there is any relationship between the two. There are various possibilities. Such a relationship may exist and be straightworward, it may exist and be more complicated, or it may in fact not exist. These three options are further explained in the detailed description.
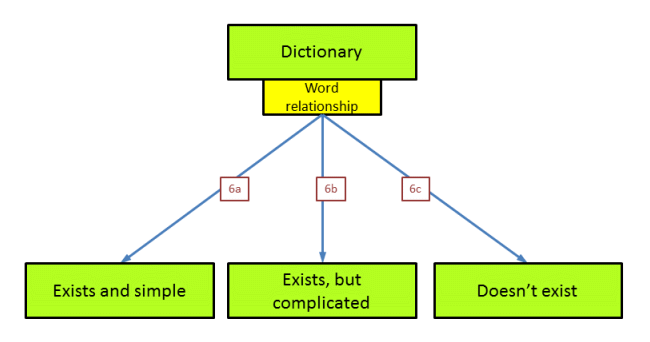
Question 6 summary
These three options are not fundamentally different, but one or two of them would have been far more practical to implement than the third. All three only play a role in case a word by word translation of the text is possible, which is far from certain.
Taking all questions and options together, we may draw a simplified version of the tree structure as shown below. In this tree, I have split the entire 'solution space' into two parts. The part A (in green) concerns the case where the text has a meaning, and a word by word translation of the text is possible. Part B (in red) concerns all other cases. It is now possible, for any proposed solution, to identify the 'box' or the category into which it falls.
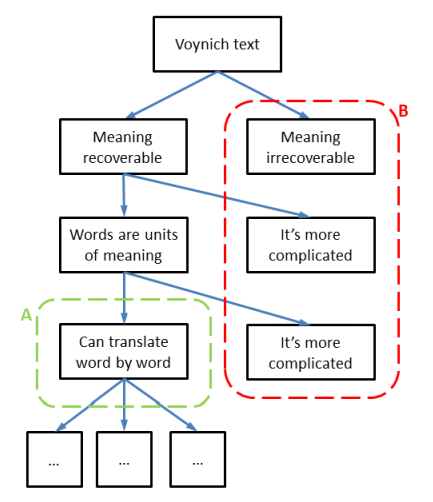
Another use of this tree structure is the demonstration that anyone who starts working on a 'solution' of the MS, by substituting Voynich characters into plain text letters in some language, is immediately jumping into the lower left box above (under the green A boundary), meaning that a whole array of hidden or subconscious descisions has been made.
Finally, one may wonder what is the likelihood that the 'truth' is in part A or in part B. This question cannot be answered, except that neither of the two probabilities are zero. I believe that the main 'divider' is the question whether the words in the MS are units of meaning. Analysing the words (both the word types and their frequency) should be able to tell us if they are, or are not, units of meaning.
The summary on this page still requires more work.
For a proper understanding of this important topic, the reader should be familiar with the meaning of entropy. A simple explanation has been provided here. The first order entropy is related to the distribution of individual characters. The second order entropy is relate to the distribution of character pairs, and says something about the possible combinations of two characters.
This topic has been discussed in literature, starting with Bennett (1976) (6). The importance of this analysis follows from the fact that entropy values do not change if a text is encrypted using a simple substitution cipher. However, the entropy values of the Voynich MS text, in particular the second order entropy, are anomalously low.
|
What we may learn from the MS text entropy |
The detailed analysis on the page linked above clearly shows that the Voynich MS text is not the result of a simple substitution cipher applied to one of the main candidate languages like Latin, Italian or German. Instead, several other alternatives remain to be explored:
While this does not seem to say much, it is a fundamental observation that tends to be ignored by most people proposing solutions to the text. This requires a bit more explanation regarding the second point, which refers to another 'quite different' language. Would Occitan, Basque, Hebrew qualify as sufficiently different? More about that question will be said in the course of the following topic.
For a proper understanding of this interesting topic, the reader should have a reasonable understanding of the principles of Hidden Markov Modelling, of which an introduction has been provided here.
This technique has been applied to the Voynich MS before, but there is very little literature about this. My own work is still in progress and available via the following link.
|
What we may learn from HMM analysis |
|
|
|
|
|
|
|
|
|
|