









|
|
|
|
|
|
|
|
|
|
The main mystery of the Voynich MS is clearly its unknown writing. This topic is addressed from three different aspects, on three (sets of) pages:
This page addresses the third part, the statistical analysis of the text. A great number of such statistical analyses has been made over the last 100+ years. Different techniques have been employed, either in order to decipher the text, or just to better understand its properties. The purpose of this part of the site is to present these analyses. While the great majority of these have been made by other people, I also include my own.
Much of the material summarised here includes hypotheses about the MS text or tentative conclusions. Hypotheses and tentative conclusions will not be the main focus of this part of the site. The aim is to collect as much information as possible. Conclusions can only be drawn after taking into account all of the available statistics.
This topic is addressed in five different areas, and the present page is the entry point into these areas, as follows:
| 1. | Introductory information |
| 2. | Character statistics |
| 3. | Word structure |
| 4. | Word statistics |
| 5. | Sentences, paragraphs, sections |
Before this, two disclaimers:
In the following, the five areas are briefly summarised.
This part (link) introduces the most common concepts used in the analysis section: Currier/RZ languages, entropy, Zipf law, etc. The reader is reminded that the analysis of the script of the MS is investigated on a separate page. There is another page dedicated to transliteration of the MS text.
The transliteration alphabet used throughout the site is the Eva alphabet, for which a more detailed description is given here. In some places, I will use small graphic files for the Voynich characters. In the present analysis section, the Voynich characters are rendered by the "Voynich EVA Hand 1" True Type font created by Gabriel Landini. This is demonstrated below, using the first paragraph of text on folio 1r of the manuscript:
The following figure was created using the Eva True Type font. The Eva text representing this section is given below it. It is then repeated, but using the Eva True Type font for the rendition.
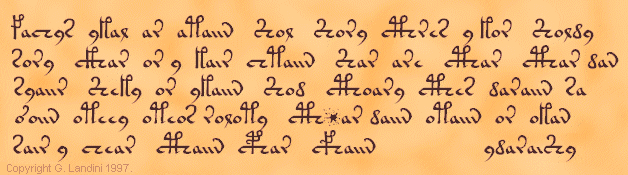
fachys ykal ar ataiin Shol Shory cThres y kor Sholdy sory cThar or y kair chtaiin Shar are cThar cThar dan syaiir Sheky or ykaiin Shod cThoary cThes daraiin sa o'oiin oteey oteor roloty cTh*ar daiin otaiin or okan sair y chear cThaiin cPhar cFhaiin ydaraiShy
fachys ykal ar ataiin Shol Shory cThres y kor Sholdy sory cThar or y kair chtaiin Shar are cThar cThar dan syaiir Sheky or ykaiin Shod cThoary cThes daraiin sa o'oiin oteey oteor roloty cTh*ar daiin otaiin or okan sair y chear cThaiin cPhar cFhaiin ydaraiShy
If the third part does not look like the Voynich script in the first picture, please see here.
The choice of the transliteration alphabet will have an impact on numerical analysis done on the Voynich MS text. This is particularly important for the calculation of the word length distribution, since the number of characters to represent one 'glyph' of the Voynich MS text is different for each alphabet. It does play a role in other statistics as well. In general, the Eva alphabet is not the most suitable for performing statistics.
This part (link) includes, among others:
When people talk about a 'word' in the Voynich MS, they refer to a string of characters separated from each other by a space in the writing. Whether these strings of characters actually represent words as we understand it, is not certain.
The analysis of the apparent words in the Voynich MS is discussed in two parts. The first part (link) treats the word struture, a unique property of the Voynich MS text.
The second part (link) includes:
This part (link) includes topics like:
|
|
|
|
|
|
|
|
|
|